
![]()
A fun technique is correlation maps. I often am looking at correlations between a
large set of attributes. Typically, this
is done with a big X by X table with correlation coefficients in every
cell. While detailed and accurate, that
make a lot of numbers for someone to look through. So these large tables full of numbers are
hard for clients to get the “big picture” of how thing interact with each
other.
A solution is to put the correlations in a “Correlation
Map”. All they are is a x,y grid with
the distance between points being proportional to the correlation. If 2 dots are close together, those two
factors are highly correlated. But if 2
dots are far apart then there is no correlation between those elements.
Since correlations are not a linear, the maps are not 100%
accurate. You can’t take a ruler and
tell exactly what the correlations coefficient is. But they are built to be generally correct,
and so even a person with no statistical background can tell what factors are
closely correlated, which ones are not, and relatively how they
interrelate. See the example below:

I have a python program (that I created) that helps me make
up these maps, but a person can just place the dots by hand based on a
correlation coefficient table.
Often when studying a large group of factors and how they
are correlated with each other, the question comes up what correlations are
direct relationships (a “driver”) and which ones are just side effects of other
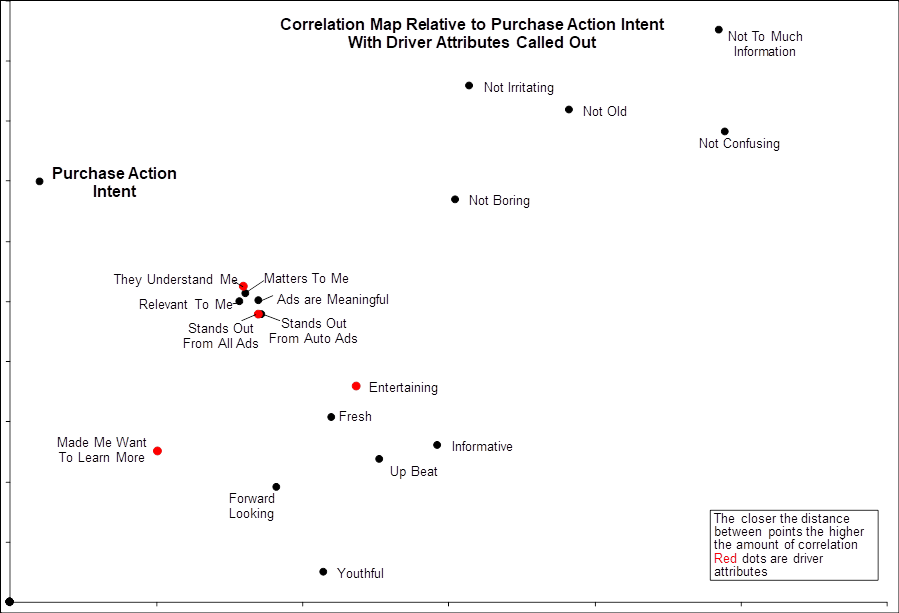
correlations. The above graph shows that
ads that are “Fresh” are also often “Up Beat” and “Informative”. But what an ad wasn’t “Up Beat” would “Fresh”
and “Informative” still go together? If
“yes”, then “Fresh” and “Informative” have a direct relationship independent of
“Up Beat”. If “no”, then “Fresh” and
“Informative” are only close (correlated) with each other because they are both
close to “Up Beat”. In the second case,
we call the relationship with “Up Beat” as the main driver.
Looking for direct relationships (drivers) is important to
making use of the correlations you see in the maps. If your goal is to get a “Purchase Action”
you want to find the direct relationships with “purchase action” to build
better ads. We call this a “Driver
analysis”. And one benefit of these
correlations maps is you can also use them to see the results of the a “driver
analysis”. Below are the results of a
driver analysis I did for a client who wanted to know which of the attributes
are the “drivers” of “Purchase Action”.
The four drivers identified can then be used to build better ads.
The science of doing a driver analysis is not that
difficult. In fact, there are many
methods all that work equally. You could
build a regression equation, and the attributes that enter the model are the
drivers. Or you can use a tree method,
identify the main driver (highest correlation), then look at where that main
driver is present and where it isn’t, and find the next driver by finding what
other attribute is highly correlated in both cases. Or Bayesian models to
remove the influence of each driver found and then look for the next one. Lots of methods.

![]()
Phone: 212-529-5337
Voice Mail: 917-838-7966
Email: Rawley.Cooper@AnalyticForensics.com
Address: 23 East Tenth Street #304
New York City, NY 10003